

September 2025 marked a significant period for Web3 fundraising, with the sector attracting $7.2 billion across 160 deals. This figure represents the highest total capital deployment since the surge observed in the spring, signaling a robust return of investor confidence. However, a closer examination of the data reveals a market predominantly fueled by late-stage capital investment, a trend that has been consistently observed over the preceding two months. The notable exception that offered a glimpse into innovative early-stage funding models was the exceptional seed-stage raise by Flying Tulip, which injected a substantial $200 million into the ecosystem at a unicorn valuation. This imbalance between late-stage dominance and early-stage capital scarcity is a key characteristic of the current Web3 investment landscape.
Market Overview: A Strong Yet Top-Heavy Landscape
At first glance, the fundraising figures for September 2025 paint a picture of renewed investor enthusiasm and a willingness to deploy capital. The $7.2 billion raised across 160 deals indicates a substantial flow of funds into the Web3 space. This capital infusion is the highest monthly total recorded since the pronounced surge witnessed in spring 2025, suggesting a potential rebound from earlier market hesitancy. However, this seemingly broad-based recovery is, in reality, heavily skewed towards later-stage companies.
The data, compiled from sources including Messari and Outlier Ventures, indicates that the vast majority of this capital was deployed into established projects rather than nascent startups. This observation aligns with insights gathered from major industry events such as Token2049 Singapore, where discussions consistently pointed towards a growing investor preference for maturity and clear pathways to liquidity. While early-stage dealmaking remains active, the significant capital injections are overwhelmingly directed towards companies that have already demonstrated product-market fit and possess established user bases or revenue streams. This trend suggests that while the overall volume of capital is impressive, the distribution indicates a focus on de-risked investments.

Market Highlight: Flying Tulip’s $200 Million Seed Round
The most significant outlier in September’s funding landscape was the extraordinary seed-stage raise by Flying Tulip. The decentralized finance (DeFi) platform secured a staggering $200 million at a $1 billion valuation, achieving unicorn status at the seed stage. This achievement is not only remarkable for its scale but also for its innovative approach to fundraising and capital deployment.
Flying Tulip aims to revolutionize the on-chain exchange experience by unifying spot trading, perpetual futures, lending, and structured yield products within a single, integrated platform. Its architecture leverages a hybrid Automated Market Maker (AMM) and order book model, facilitates cross-chain deposits, and incorporates advanced features like volatility-adjusted lending. This ambitious vision, coupled with the substantial seed funding, underscores a growing appetite for sophisticated DeFi infrastructure that can bridge the gap between traditional finance and the decentralized world.
Further analysis of Flying Tulip’s funding structure reveals a departure from conventional seed-stage investment models. The platform’s unique on-chain redemption rights offer investors a degree of capital security and direct yield exposure, a compelling proposition that mitigates some of the inherent risks associated with early-stage ventures. Crucially, Flying Tulip is not simply holding its raised capital; it is actively deploying it within DeFi protocols to generate yield. This yield is then strategically utilized to fund ongoing growth initiatives, incentivize user participation, and implement buyback programs. This capital-efficient model, where the raised funds themselves become a revenue-generating asset, represents a significant innovation in how Web3 protocols can finance their development and expansion.
This DeFi-native approach to capital efficiency could potentially redefine fundraising strategies for future protocols. While Flying Tulip’s investors retain the right to withdraw their funds at any point, the sheer scale of this investment signifies a substantial commitment from Web3 venture capitalists. This investment, rather than being channeled into more illiquid instruments like SAFEs (Simple Agreement for Future Equity) or SAFTs (Simple Agreement for Future Tokens) that are typical for early-stage funding, highlights a prevailing trend among Web3 investors seeking greater liquidity and more direct exposure to yield-generating opportunities.
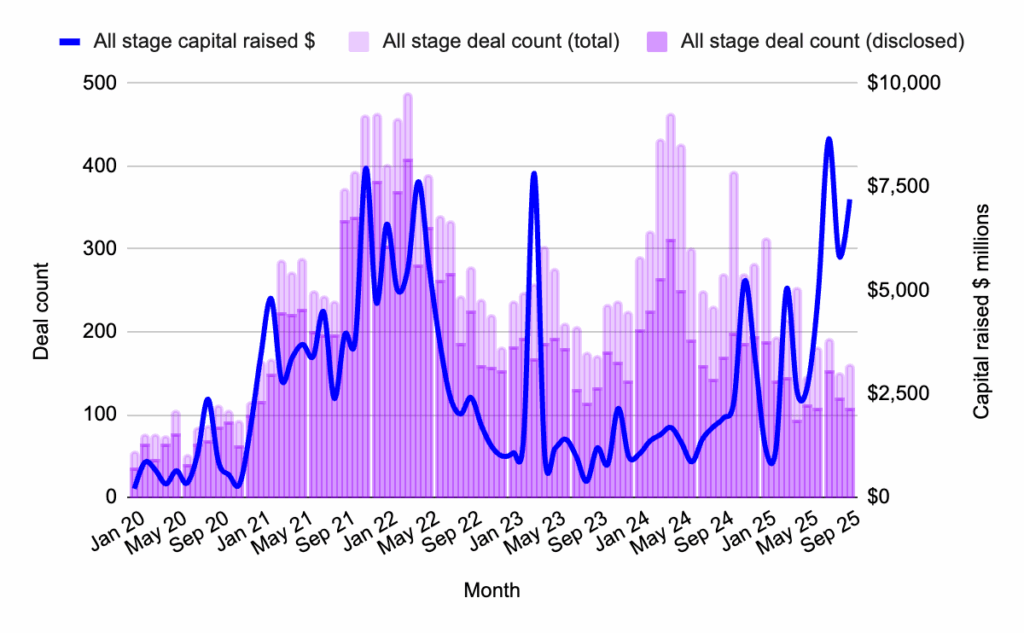
New Crypto/Web3 Venture Funds: A Shift Towards Sharper Theses
September 2025 saw a discernible cooling in the pace of new venture fund formation within the crypto and Web3 space. Only two new investment vehicles were launched during the month, and both were characterized by their relatively smaller size and highly thematic investment focus. This trend suggests a move towards greater selectivity and a more targeted approach to capital allocation rather than a general slowdown in fund raising. Venture capital firms are actively raising capital, but they are increasingly doing so with very specific and refined investment theses.
This strategic recalibration by VCs indicates a maturation of the market, where investors are looking to capitalize on specific niches and emerging trends rather than broad market plays. The emphasis is on identifying and supporting projects with unique value propositions and clear potential for disruption within their respective domains. This approach allows for more efficient deployment of capital and a deeper engagement with the underlying technologies and market dynamics.
Pre-Seed Rounds: A Persistent Downward Trend
Pre-seed funding continued its downward trajectory throughout September 2025, exhibiting a consistent slump in both the number of deals and the total capital raised. This stage of early-stage investment has remained sluggish for nine consecutive months, characterized by a scarcity of capital and limited participation from major investors.
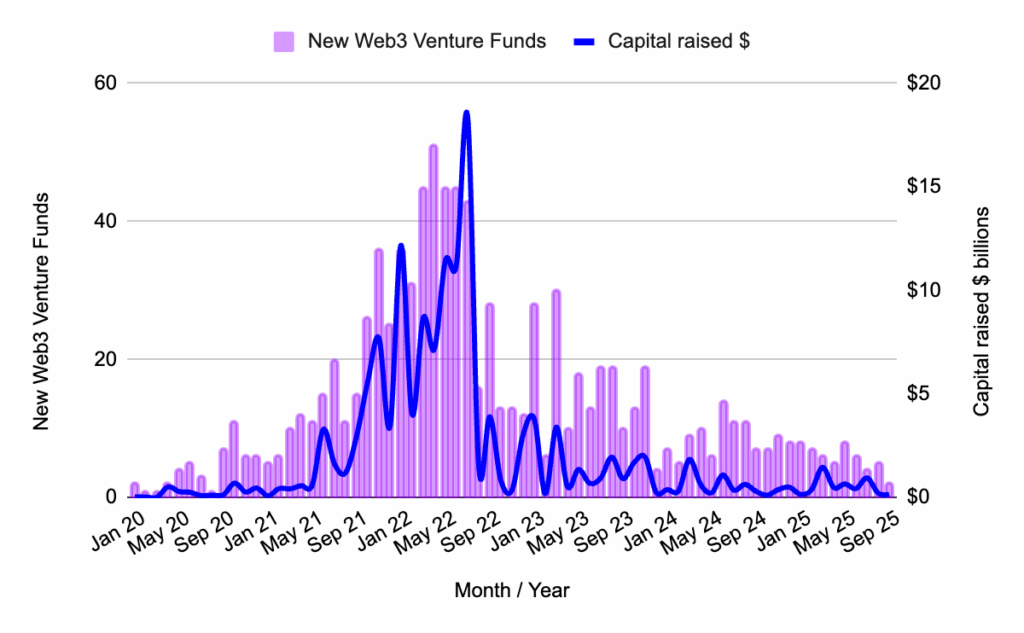
For founders at the pre-seed stage, securing funding remains a significant challenge. The environment demands exceptionally tight narratives, a clear articulation of technical conviction, and a compelling vision for future growth. While capital is scarce, projects that manage to secure funding are typically those that can demonstrate a strong understanding of their market, a robust technical foundation, and a clear path to product development and user acquisition.
Pre-Seed Highlight: Melee Markets ($3.5 Million)
Despite the overall downturn, a notable pre-seed round emerged from Melee Markets. Built on the Solana blockchain, Melee Markets offers users a platform to speculate on influencers, events, and trending topics, effectively blending prediction markets with social trading functionalities. Backed by prominent investors such as Variant and DBA, the project represents an innovative attempt to capture and monetize attention flow as a distinct asset class. This initiative taps into the growing trend of creating markets around intangible assets and user engagement, reflecting a forward-thinking approach to value creation in the digital realm.
Seed Rounds: The Flying Tulip Effect
Seed-stage funding in September 2025 experienced a significant boost, largely attributable to the aforementioned $200 million raise by Flying Tulip. Without this singular, substantial investment, the seed stage would have shown performance broadly in line with previous months, underscoring the impact of this one deal on the overall figures.
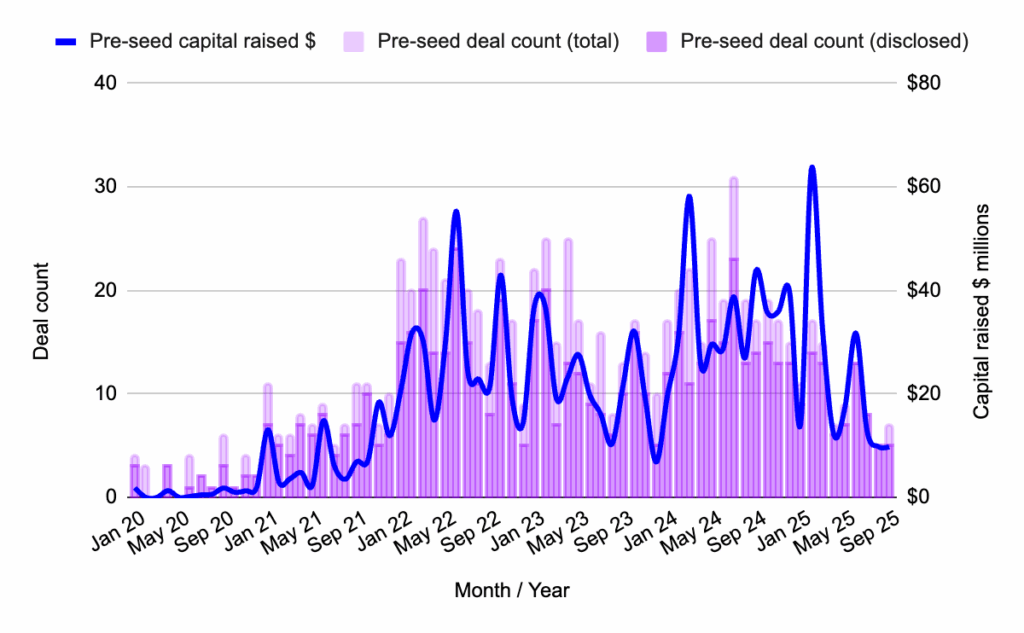
Beyond the headline number, Flying Tulip’s innovative fundraising structure offers profound implications for the future of seed-stage capital allocation. Its unique on-chain redemption rights provide investors with a dual benefit: capital security, a rare commodity in early-stage investing, coupled with direct exposure to yield generation. This hybrid model, where capital is raised not just for operational expenses but also to generate returns through DeFi yield farming, presents a paradigm shift. The protocol strategically employs its raised funds to fuel growth, incentivize ecosystem participation, and facilitate token buybacks, showcasing a sophisticated approach to capital efficiency.
The structure essentially transforms the seed round into a yield-bearing asset for investors, a departure from traditional equity-like instruments. This mechanism allows Flying Tulip to access substantial capital while simultaneously offering investors a more attractive risk-reward profile. While the investors retain the right to redeem their capital, the inherent yield-generating capacity of the raised funds incentivizes long-term commitment. This innovative approach to seed funding, driven by DeFi principles, could serve as a blueprint for other early-stage Web3 projects seeking to attract significant investment in a capital-constrained environment. It also represents a clear manifestation of the growing demand among Web3 investors for more liquid and yield-generating asset exposure.
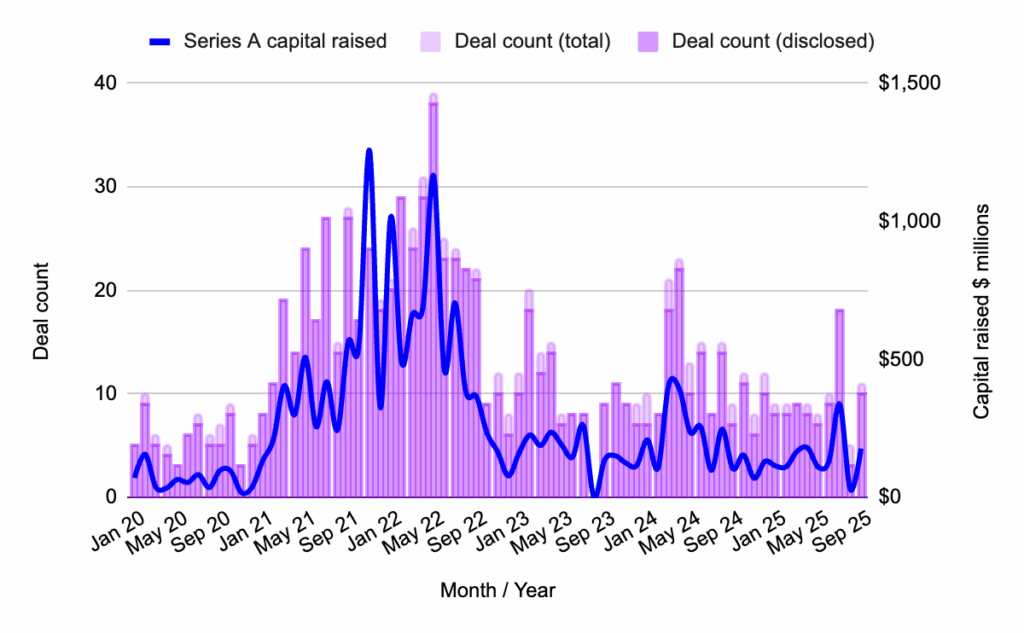
Series A: A Stabilizing Market
Following a sharp decline in August, Series A funding demonstrated a modest recovery in September 2025. While not a breakout month, deal volume and capital deployed hovered around the average observed throughout 2025. This indicates a period of stabilization for Series A rounds, with investors maintaining a cautious and selective approach.
The current trend at this stage suggests a preference for projects that can showcase established traction and clear product-market fit, rather than those relying solely on early-stage momentum. Investors are looking for demonstrable progress and a solid foundation upon which to build.
Series A Highlight: Digital Entertainment Asset ($38 Million)
A notable Series A funding round was secured by Singapore-based Digital Entertainment Asset (DEA). The company raised $38 million to advance its initiatives in building Web3 gaming, Environmental, Social, and Governance (ESG) platforms, and advertising solutions that offer real-world payouts. Supported by prominent investors such as SBI Holdings and ASICS Ventures, DEA’s funding round reflects Asia’s sustained interest in integrating blockchain technology with mainstream consumer industries. This investment highlights the growing convergence of gaming, digital assets, and real-world applications, signaling a promising future for interactive entertainment and its monetization models.
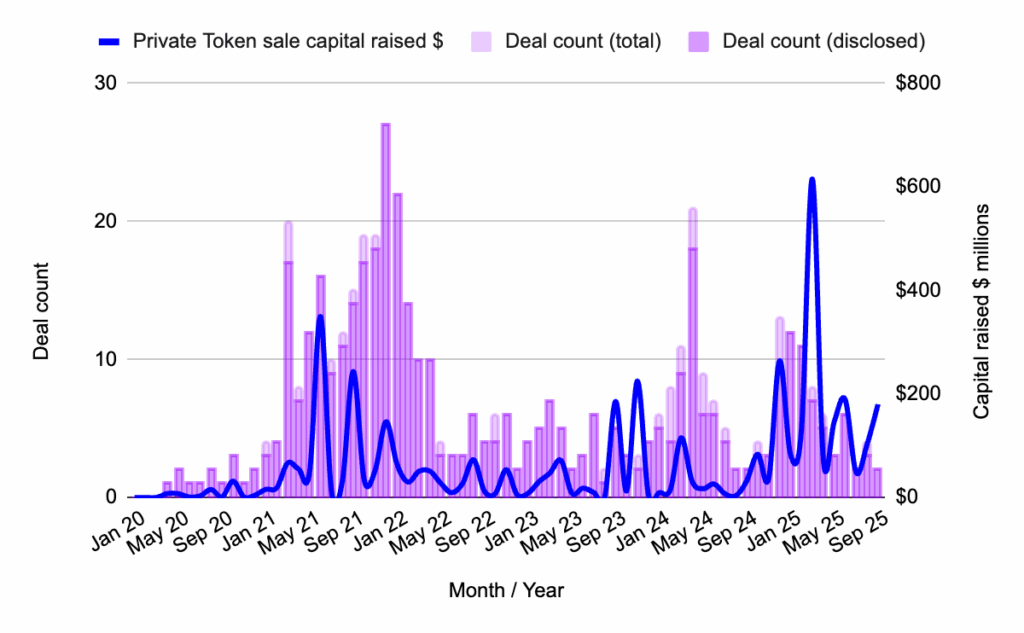
Private Token Sales: Concentration of Capital
Activity in private token sales remained highly concentrated in September 2025, with a single, substantial raise accounting for the majority of the capital deployed. This pattern, observed in recent months, continues to show a trend of fewer, larger token rounds, with exchange-driven initiatives absorbing a significant portion of the available liquidity.
This concentration indicates that large, established players and projects with strong exchange partnerships are currently dominating the private token sale market. The focus is on strategic placements that can ensure liquidity and broad market access upon token launch.
Highlight: Crypto.com ($178 Million)
Crypto.com, a leading cryptocurrency exchange, secured a significant $178 million in private funding. Reports suggest this raise was conducted in partnership with Trump Media. This substantial capital injection underscores Crypto.com’s continued ambition to expand its global reach and develop tools for mass-market cryptocurrency adoption and spending. While the specifics of the partnership remain subject to interpretation, whether a strategic brand pivot or a calculated public relations maneuver, the move has certainly captured attention within the industry. This funding will likely be directed towards enhancing its product offerings, expanding its user base, and strengthening its market position in the competitive cryptocurrency exchange landscape.
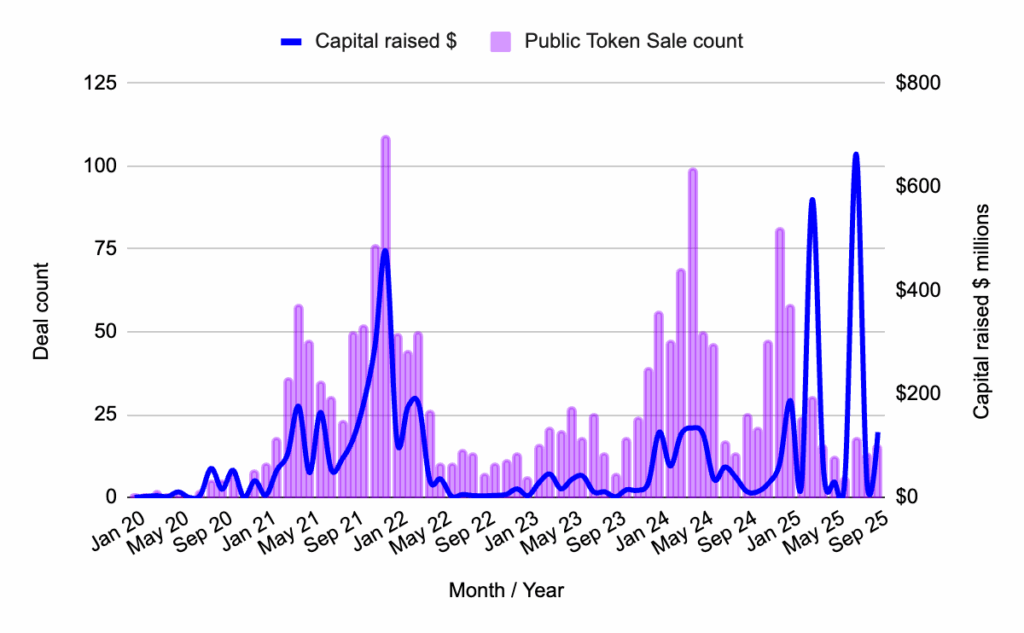
Public Token Sales: The Rise of Bitcoin Yield (BTCFi)
Public token sales remained a dynamic sector in September 2025, largely driven by two dominant narratives: Bitcoin yield generation (BTCFi) and advancements in Artificial Intelligence (AI) agents. This sustained activity in public markets serves as a reminder that narrative-driven investment continues to be a significant factor in the crypto space.
The growing interest in BTCFi signals a maturation of the Bitcoin ecosystem, with increasing efforts to integrate Bitcoin into the broader DeFi landscape and unlock its yield-generating potential. This trend suggests that Bitcoin is evolving beyond its role as a store of value and is becoming a more active participant in decentralized finance.
Highlight: Lombard ($94.7 Million)
Lombard emerged as a key player in the public token sale arena, raising $94.7 million. The company is focused on bringing Bitcoin into the DeFi ecosystem through its introduction of LBTC. This liquid BTC asset is designed to be yield-bearing and cross-chain, aiming to unify Bitcoin liquidity across various decentralized networks. Lombard’s initiative is a prime example of the burgeoning "BTCFi" trend, where Bitcoin is increasingly being engineered to generate yield, thereby enhancing its utility and appeal within the decentralized finance space. This development is crucial for unlocking greater value and utility for Bitcoin holders.
Recruiting Now: Injective Ecosystem Builder Catalyst
The current investment climate underscores a clear investor preference for sharper, more compelling narratives, robust infrastructure, and founders adept at aligning with powerful, established ecosystems. This is precisely the environment for which the Injective Ecosystem Cohort program is designed.
The Injective Ecosystem Builder Catalyst program is specifically curated to support early-stage teams building within one of Web3’s most influential ecosystems. Whether the focus is on developing the next generation of decentralized finance (DeFi) protocols, enhancing cross-chain liquidity, or pioneering innovations in trading, derivatives, and decentralized infrastructure, the program aims to empower teams to transform their conviction into tangible traction. Applications for this cohort are currently open, offering a unique opportunity for ambitious builders to leverage the resources and network of the Injective ecosystem.
Conclusion: Late-Stage Dominance and Emerging Innovations
In summary, September 2025’s Web3 fundraising landscape was characterized by a strong inflow of capital, primarily driven by late-stage investments and significant token raises. While early-stage activity remained relatively subdued, the exceptional seed-stage round by Flying Tulip offered a compelling glimpse into potentially transformative fundraising models for the future. However, for the present, this innovative approach remains an outlier rather than the established norm, with the market continuing to favor maturity and proven traction. The ongoing trends indicate a strategic shift towards more targeted investments and a growing emphasis on liquidity and yield generation within the Web3 capital markets.





